AI Request Routing est une capacité d’infrastructure conçue pour gérer les ressources d’inférence multi-modèles. Avec l’évolution continue des grands modèles de langage tels que GPT, Claude, Gemini et DeepSeek, un nombre croissant d’applications d’IA intègrent désormais plusieurs modèles simultanément. Savoir choisir intelligemment entre différents modèles est devenu un enjeu majeur dans la conception des systèmes d’IA.
Gate.AI se positionne entre les applications et les services de modèles en tant que passerelle d’IA et couche de routage. Alors que les architectures multi-modèles s’imposent comme la norme du secteur, le routage de modèles influence non seulement les performances du système, mais aussi la maîtrise des coûts, la stabilité des services et les capacités autonomes des agents d’IA.
Qu’est-ce que le routage de requêtes d’IA ?
Mécanisme d’ordonnancement qui sélectionne automatiquement un modèle cible en fonction des caractéristiques de la tâche, le routage de requêtes d’IA repose, dans les architectures traditionnelles, sur l’appel d’un modèle fixe unique par une application pour réaliser des tâches d’inférence. Dans une architecture multi-modèles, chaque modèle offre des avantages distincts : capacité de raisonnement, génération de code, traitement de longs textes ou efficacité des coûts.
La couche de routage analyse le contenu de la requête et l’achemine vers le modèle le plus adapté à son exécution, optimisant ainsi l’utilisation globale des ressources.
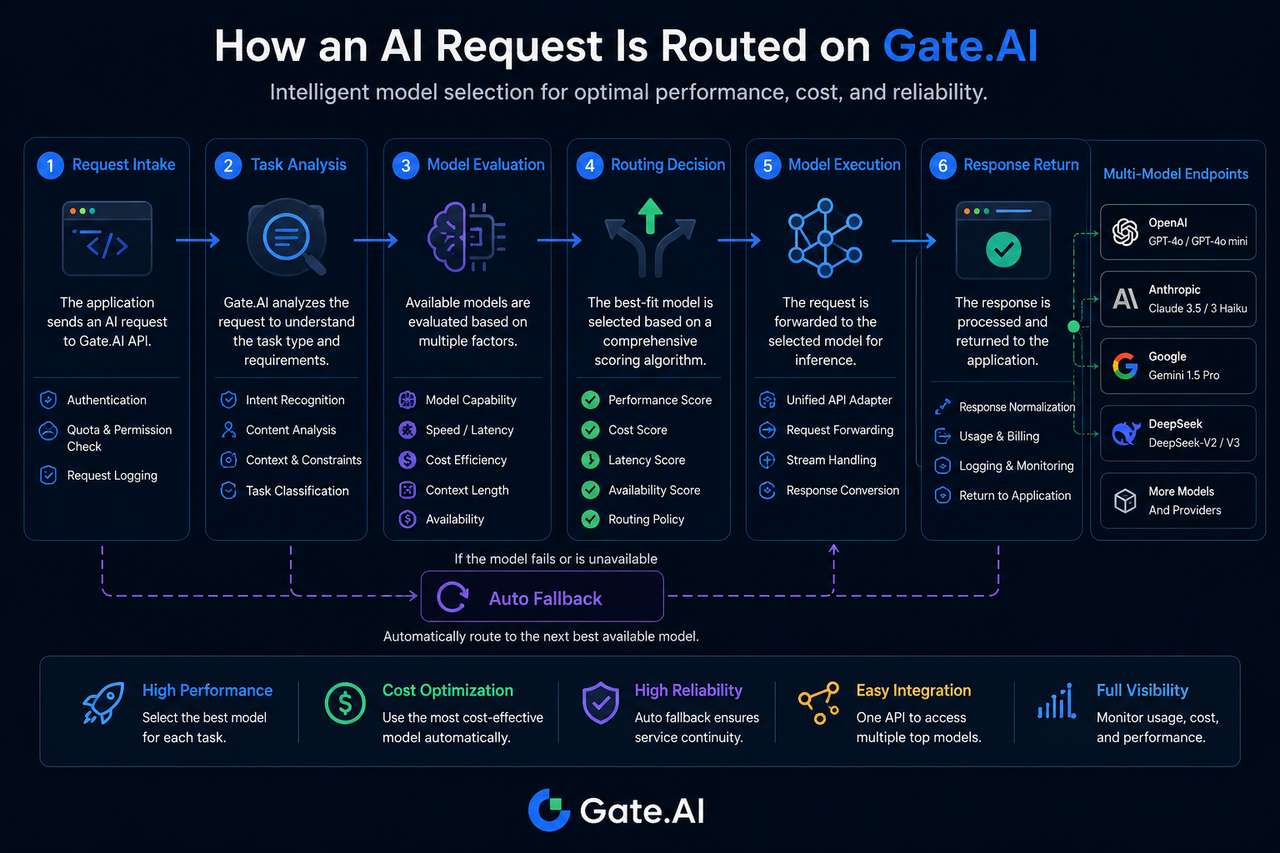
Étape 1 : La requête d’IA entre dans Gate.AI
Tout processus de routage commence par la phase d’accès à la requête.
Lorsqu’une application envoie une requête, celle-ci parvient d’abord à la couche de passerelle Gate.AI. Le système vérifie alors les informations d’identité, contrôle les autorisations d’accès et enregistre les paramètres de la requête.
Le contenu de la requête comprend généralement :
- la saisie de l’utilisateur ;
- la configuration du modèle ;
- les limites de tokens ;
- les exigences de format de réponse ;
- la stratégie d’invocation.
Après vérification, la requête passe à la phase d’analyse suivante.
Étape 2 : Le système analyse le type de tâche
L’identification de la tâche est un élément clé du routage de modèles.
Gate.AI détermine le type de tâche en fonction des caractéristiques de la requête, par exemple :
- conversation générale ;
- résumé de longs textes ;
- création de contenu ;
- génération de code ;
- analyse de données ;
- appels d’outils d’agent.
Les besoins en capacités des modèles varient considérablement selon les tâches.
Une identification précise de la tâche rend l’appariement ultérieur des modèles plus efficace.
Étape 3 : Évaluation et appariement des capacités des modèles
La phase d’évaluation des modèles détermine la plage des modèles candidats.
Le système consulte la base de données des capacités des modèles pour filtrer ceux qui sont actuellement disponibles.
Les dimensions d’évaluation comprennent généralement :
- la capacité de raisonnement ;
- la longueur du contexte ;
- la vitesse de réponse ;
- la capacité d’appel d’outils ;
- le support multimodal ;
- le niveau de coût.
Par exemple, les tâches de raisonnement complexes privilégient les modèles aux capacités de raisonnement plus poussées, tandis que les tâches de traitement de longs documents favorisent ceux prenant en charge des fenêtres de contexte ultra-longues.
Étape 4 : Générer la décision de routage
La phase de décision de routage détermine le modèle d’exécution final.
Une fois les modèles candidats identifiés, le système les note en combinant plusieurs métriques.
Les facteurs de référence courants incluent :
Performances du modèle
Les performances du modèle déterminent la qualité d’achèvement de la tâche.
Les problèmes complexes nécessitent généralement un raisonnement logique plus fort, tandis que les tâches simples peuvent se contenter d’un modèle moins performant.
Latence de réponse
La vitesse de réponse impacte directement l’expérience utilisateur.
Pour les scénarios d’interaction en temps réel, les modèles à faible latence reçoivent souvent une priorité plus élevée.
Coût d’invocation
Les coûts d’inférence varient selon les modèles.
Lorsque plusieurs modèles peuvent effectuer la même tâche, le système peut privilégier celui offrant la meilleure efficacité des ressources.
Disponibilité du service
L’état du modèle est également un facteur important dans les décisions de routage.
Si un modèle est limité en débit, rencontre des défaillances ou est congestionné, le système abaisse automatiquement sa priorité.
Étape 5 : La requête est envoyée au modèle cible
Une fois la décision de routage prise, la requête est transmise au modèle cible.
À ce stade, Gate.AI harmonise les différences d’interface entre les divers fournisseurs de modèles.
Les développeurs d’applications n’ont pas besoin de développer des interfaces distinctes pour chaque modèle.
Une couche d’accès unifiée réduit la complexité de développement et améliore l’évolutivité du système.
Étape 6 : Le modèle génère le résultat et le renvoie
Une fois que le modèle cible a terminé l’inférence, le résultat est renvoyé à Gate.AI.
Gate.AI normalise la réponse, garantissant des structures de données cohérentes, quel que soit le modèle.
Un format de sortie unifié réduit le travail d’adaptation au niveau applicatif et simplifie l’intégration ultérieure du système.
Le résultat final est renvoyé à l’application ou à l’agent d’IA.
Que se passe-t-il lorsque le modèle cible est indisponible ?
L’indisponibilité du modèle est un phénomène courant dans un écosystème multi-modèles.
Si le modèle cible expire, est limité en débit ou présente des anomalies de service, Gate.AI peut déclencher un processus de repli automatique.
Le système resélectionne un modèle de secours selon des politiques prédéfinies pour continuer à exécuter la tâche.
Ce mécanisme réduit le risque de point de défaillance unique et améliore la continuité globale du service.
Pour en savoir plus, consultez « Que se passe-t-il lorsqu’un modèle d’IA échoue ? Analyse complète du mécanisme de repli automatique de Gate.AI. »
Exemple d’un processus de routage de requêtes d’IA
L’exemple suivant illustre un flux typique pour une tâche de génération de contenu :
| Phase |
Action du système |
| Accès à la requête |
L’application envoie une demande de génération |
| Analyse de la tâche |
Identifiée comme création de contenu long |
| Filtrage des modèles |
Sélection des modèles candidats prenant en charge le contexte long |
| Décision de routage |
Notation basée sur les performances, le coût et la latence |
| Exécution du modèle |
Requête envoyée au modèle cible |
| Traitement du résultat |
Renvoi d’une sortie normalisée |
| Reprise après échec |
Basculement automatique vers le modèle de secours si nécessaire |
Ce processus est généralement terminé en très peu de temps, et les utilisateurs ne perçoivent souvent pas la sélection du modèle en arrière-plan.
Résumé
Capacité centrale de la passerelle d’IA, le routage de requêtes d’IA sélectionne dynamiquement le modèle le plus adapté pour exécuter une tâche parmi plusieurs grands modèles de langage. Contrairement à l’appel fixe d’un modèle unique, le routage de modèles exploite pleinement les atouts de chaque modèle, améliorant ainsi la flexibilité, la stabilité et l’utilisation des ressources du système.
Dans l’architecture Gate.AI, une requête d’IA passe par plusieurs étapes : accès à la requête, identification de la tâche, évaluation du modèle, décision de routage, exécution du modèle et renvoi du résultat.
FAQ
Pourquoi Gate.AI a-t-il besoin d’un routage de modèles ?
Gate.AI connecte plusieurs écosystèmes de modèles d’IA, où chaque modèle excelle dans des domaines comme le raisonnement, la génération de code ou le traitement de longs textes. Le routage de modèles sélectionne automatiquement le modèle le plus adapté en fonction des exigences de la tâche.
Une même requête d’IA peut-elle appeler plusieurs modèles en même temps ?
En règle générale, une seule requête d’IA est exécutée par un modèle cible. Cependant, dans certains scénarios complexes, un modèle de collaboration multi-modèles peut être utilisé, où différents modèles traitent différentes parties de la tâche.
Quels sont les principaux facteurs pris en compte dans les décisions de routage de l’IA ?
Les décisions de routage de l’IA prennent généralement en compte plusieurs facteurs : performances du modèle, vitesse de réponse, coût d’inférence, longueur du contexte, capacité d’appel d’outils et disponibilité du service.
Quelle est la différence entre le routage de modèles et l’équilibrage de charge ?
L’équilibrage de charge traite principalement de la répartition du trafic, tandis que le routage de modèles se concentre sur l’appariement des capacités des modèles. Le routage de modèles sélectionne le modèle le plus adapté en fonction des caractéristiques de la tâche, et non simplement en distribuant le trafic des requêtes.








