Kebangkitan artificial Intelligence tengah mengubah lanskap industri semikonduktor global. Permintaan akan model bahasa besar, AI generatif, dan komputasi berperforma tinggi terus meningkat, mendorong volume data yang harus diolah oleh chip komputasi tumbuh secara eksponensial. Di tengah kondisi ini, teknologi memori konvensional mulai mencapai batas bandwidth dan efisiensi daya. Sementara itu, HBM (High Bandwidth Memory)—yang mampu mentransfer data dengan kecepatan sangat tinggi—kini menjadi pilar utama infrastruktur AI.
Di pasar HBM global, SK Hynix menempati posisi yang sangat strategis. Sebagai salah satu produsen chip memori terdepan di dunia, SK Hynix tidak hanya menguasai teknologi DRAM secara mendalam, tetapi juga menjadi pionir dalam pengembangan dan produksi massal HBM. Seiring kebutuhan GPU AI akan memori yang semakin cepat, SK Hynix pun menjelma menjadi pemasok utama dalam rantai pasokan chip memori AI.
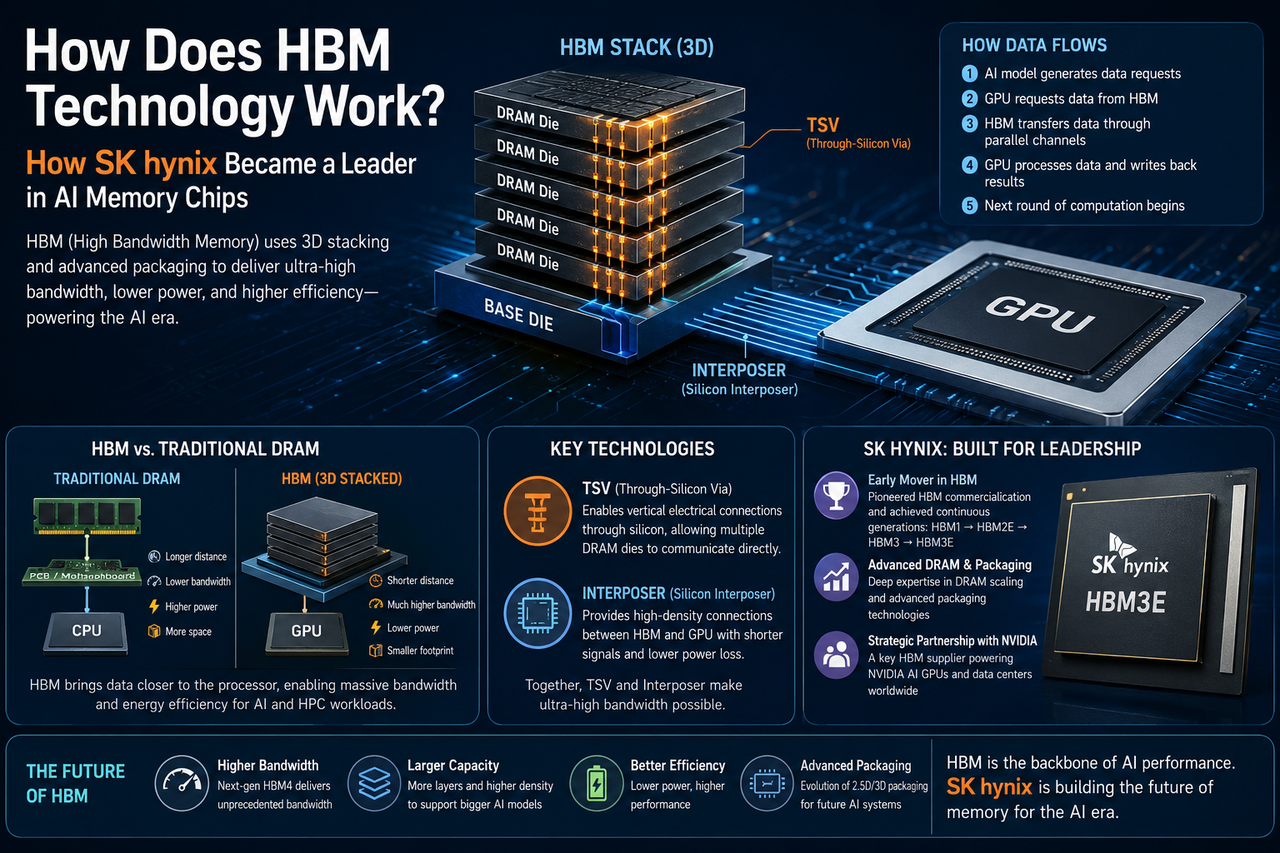
Apa Itu HBM?
HBM (High Bandwidth Memory) adalah teknologi memori ber-bandwidth tinggi yang dirancang khusus untuk kebutuhan AI, komputasi berperforma tinggi (HPC), pusat data, dan pemrosesan grafis. Dibandingkan dengan DRAM biasa, HBM mampu memberikan throughput data yang jauh lebih besar dalam ukuran fisik yang jauh lebih ringkas.
Inovasi utama HBM terletak pada arsitektur tumpuk tiga dimensi (3D). Beberapa chip DRAM ditumpuk secara vertikal dan dihubungkan dengan kecepatan tinggi melalui teknologi TSV (Through-Silicon Via). Karena jarak tempuh data lebih pendek, HBM mampu meningkatkan bandwidth secara drastis sekaligus menekan konsumsi daya.
Mengapa DRAM Konvensional Tidak Lagi Memadai untuk AI
Selama bertahun-tahun, DRAM konvensional menjadi andalan solusi memori untuk komputer dan server. Namun, kebutuhan data di era AI kini telah jauh melampaui kemampuan komputasi tradisional.
Dalam proses pelatihan model besar, GPU harus terus-menerus membaca dan menulis parameter dalam jumlah masif. Jika pasokan data tidak cukup cepat untuk mengimbangi GPU, prosesor tercanggih sekalipun akan banyak membuang siklus komputasi hanya untuk menunggu.
DRAM konvensional menghadapi kendala berikut:
| Tantangan |
Kinerja DRAM Konvensional |
| Batas bandwidth |
Throughput data terbatas |
| Konsumsi daya tinggi |
Jalur data lebih panjang meningkatkan pemakaian energi |
| Ukuran fisik besar |
Sulit ditempatkan di lingkungan padat |
| Skalabilitas AI |
Efisiensi menurun pada konfigurasi multi-GPU |
Karena itulah industri beralih ke arsitektur memori baru yang lebih sesuai dengan AI—dan HBM pun menjadi primadona.
Cara Kerja Teknologi HBM
Ide utama HBM adalah memperpendek jarak tempuh data dan menambah jumlah saluran data secara signifikan.
DRAM konvensional terhubung ke prosesor melalui motherboard. Sebaliknya, HBM dikemas langsung di samping GPU. Beberapa die DRAM ditumpuk vertikal menggunakan TSV, lalu dihubungkan ke GPU melalui interposer silikon untuk menghasilkan komunikasi ber-bandwidth sangat tinggi.
Alur data berjalan seperti berikut:
- Model AI yang berjalan di GPU menghasilkan aliran permintaan data yang terus-menerus.
- GPU mengirim perintah baca ke HBM.
- HBM mengembalikan data melalui banyak saluran paralel dengan kecepatan tinggi.
- Setelah selesai diproses, GPU menulis hasilnya kembali ke memori.
- Siklus komputasi berikutnya dimulai segera.
Desain ini meminimalkan latensi akibat perpindahan data dan secara drastis meningkatkan efisiensi pelatihan AI.
Perbedaan Struktural HBM vs. DRAM Konvensional
| Dimensi |
HBM |
DRAM Konvensional |
| Arsitektur chip |
Tumpukan 3D |
Tata letak planar |
| Interkoneksi data |
TSV + Interposer |
Jejak PCB |
| Bandwidth |
Sangat tinggi |
Sedang |
| Konsumsi daya |
Lebih rendah |
Lebih tinggi |
| Penggunaan utama |
AI, GPU, HPC |
PC, server |
Mengapa TSV dan Interposer Begitu Krusial
TSV (Through-Silicon Via) adalah teknologi dasar yang memungkinkan penumpukan 3D pada HBM. TSV menciptakan jalur vertikal di dalam chip, sehingga lapisan memori yang ditumpuk dapat saling berkomunikasi secara langsung. Interposer silikon berfungsi sebagai jembatan penghubung antara GPU dan HBM, menyediakan jalur data yang jauh lebih padat dan mengurangi kehilangan sinyal dibandingkan jejak motherboard konvensional.
Kedua teknologi ini menjadi fondasi arsitektur HBM dan alasan utama mengapa HBM mampu mencapai bandwidth yang sangat ekstrem.
Peran HBM dalam Pelatihan AI
Model AI modern berisi miliaran hingga triliunan parameter. Setiap sesi pelatihan membutuhkan pembacaan kumpulan data yang sangat besar.
Jika GPU memproses data lebih cepat daripada pasokan data, maka sistem akan mengalami waktu tunggu yang menganggur. Tugas HBM adalah menjaga jalur data tetap penuh sehingga GPU dapat bekerja pada efisiensi maksimal.
Dalam inferensi AI, HBM juga sama pentingnya. Akses memori yang cepat mempercepat waktu respons dan meningkatkan performa model. Inilah alasan HBM menjadi komponen yang tak tergantikan dalam desain chip AI.
Bagaimana SK Hynix Menjadi Pemimpin HBM
SK Hynix memiliki fondasi kuat di bidang teknologi DRAM, yang menjadi landasan bagi terobosan HBM-nya.
Perusahaan ini termasuk yang pertama mengomersialkan HBM. Dari HBM1 hingga HBM3E, SK Hynix secara konsisten mendorong batas kemampuan bandwidth, kapasitas, efisiensi energi, dan teknologi pengemasan canggih.

Sebelum ledakan AI, pasar HBM relatif kecil. Namun SK Hynix terus berinvestasi dalam riset dan pengembangan. Ketika AI generatif dan model besar memicu lonjakan permintaan, SK Hynix sudah memiliki teknologi matang dan kapasitas produksi yang siap pakai.
Posisi strategis jangka panjang inilah yang memberi SK Hynix keunggulan kompetitif yang sulit ditandingi.
SK Hynix dan NVIDIA: Kemitraan Strategis
GPU AI merupakan pasar aplikasi terbesar bagi HBM, dan NVIDIA adalah pemain dominan di industri chip AI.
GPU AI kelas atas saat ini membutuhkan subsistem memori berkapasitas besar dan ber-bandwidth tinggi. HBM telah menjadi standar pada GPU premium, dan SK Hynix adalah pemasok utama HBM.
Hubungan ini memungkinkan SK Hynix memainkan peran sentral dalam pembangunan infrastruktur AI—dan semakin memperkuat posisi strategisnya dalam rantai pasokan semikonduktor global.
Masa Depan HBM
Seiring model AI yang terus membesar, teknologi HBM juga terus berevolusi.
Tren utama yang akan datang:
| Arah Teknologi |
Tujuan |
| HBM4 |
Bandwidth dan kapasitas yang lebih tinggi |
| Lebih banyak lapisan tumpukan |
Kepadatan memori lebih besar |
| Pengemasan canggih |
Latensi dan daya lebih rendah |
| Memori yang dioptimalkan untuk AI |
Efisiensi pelatihan lebih baik |
| Integrasi chiplet |
Skalabilitas sistem meningkat |
Ke depannya, peningkatan performa chip AI tidak hanya bergantung pada GPU itu sendiri, tetapi juga pada inovasi dari sisi memori.
HBM vs. GDDR: Apa Bedanya?
Baik HBM maupun GDDR adalah memori berperforma tinggi, tetapi dirancang untuk tujuan yang berbeda.
GDDR dibuat untuk kartu grafis konsumen, meningkatkan kecepatan melalui frekuensi clock yang lebih tinggi. Sementara itu, HBM mencapai performa tinggi berkat bus ultra-lebar dan penumpukan vertikal, sehingga menghasilkan bandwidth lebih tinggi dan daya lebih rendah. Dalam pelatihan AI, HPC, dan lingkungan pusat data, HBM jelas lebih unggul.
Kesimpulan
HBM adalah salah satu teknologi memori terpenting di era AI. Melalui penumpukan 3D, TSV, dan interposer silikon, HBM mampu memberikan bandwidth yang jauh melampaui DRAM konvensional. Dengan meningkatnya kebutuhan pelatihan model besar dan komputasi berperforma tinggi, HBM telah menjadi komponen esensial pada GPU AI dan infrastruktur pusat data.
Berkat penguasaan teknologi DRAM selama puluhan tahun, keahlian dalam pengemasan canggih, serta investasi yang konsisten di HBM, SK Hynix telah memantapkan posisinya sebagai pemimpin global. Mulai dari chip AI, pusat data, GPU, hingga superkomputer—HBM menjadi motor penggerak komputasi AI, dan SK Hynix berada di pusat rantai pasokan yang krusial ini.
FAQ
Mengapa HBM lebih baik untuk AI dibandingkan DRAM konvensional?
HBM menawarkan bandwidth yang jauh lebih tinggi, latensi lebih rendah, dan konsumsi daya lebih kecil. Pelatihan model AI terus-menerus membaca kumpulan data yang sangat besar, menjadikan HBM pilihan yang jauh lebih sesuai untuk kebutuhan memori GPU.
Apa itu teknologi TSV?
TSV (Through-Silicon Via) adalah teknologi yang menciptakan sambungan listrik vertikal di dalam chip yang ditumpuk. HBM memanfaatkan TSV untuk mewujudkan pengemasan 3D yang padat.
Apa perbedaan antara HBM dan GDDR?
GDDR dirancang untuk rendering grafis, sedangkan HBM dibuat untuk AI, HPC, dan pusat data. HBM umumnya menawarkan bandwidth dan efisiensi energi yang lebih unggul.
Mengapa SK Hynix memimpin pasar HBM?
SK Hynix telah berinvestasi di HBM sejak tahap awal dan memiliki keahlian mendalam dalam manufaktur DRAM serta teknologi pengemasan canggih. Ketika permintaan AI melonjak, perusahaan sudah memiliki produk matang dan kapasitas produksi yang siap untuk diperbesar.
Apa yang akan berubah dengan HBM4?
HBM4 diperkirakan akan mendorong peningkatan lebih lanjut pada bandwidth, kapasitas, dan efisiensi energi, sehingga mampu mendukung beban kerja pelatihan AI yang lebih besar. Seiring komputasi AI terus berkembang, HBM4 diyakini akan menjadi solusi memori andalan untuk platform berperforma tinggi generasi berikutnya.








