À medida que os grandes modelos de linguagem (LLM) se tornam infraestrutura crítica para aplicações de IA, os programadores que desenvolvem assistentes inteligentes, fluxos de trabalho automatizados e agentes de IA veem-se frequentemente perante uma escolha: invocar diretamente a API da OpenAI ou utilizar uma plataforma AI Gateway para centralizar a gestão de chamadas a modelos. Ambas as abordagens habilitam funcionalidades de IA, mas diferem substancialmente na arquitetura do sistema, escalabilidade e complexidade operacional.
Num contexto de ecossistema multi-modelo em evolução, as empresas e os programadores preferem cada vez mais utilizar vários modelos em simultâneo — como GPT, Claude, Gemini e DeepSeek. A forma de gerir de forma centralizada os recursos dos modelos, reduzir o risco de dependência de fornecedores e melhorar a disponibilidade do sistema tornou-se um tema crítico na infraestrutura de IA. A Gate.AI surgiu precisamente como plataforma de routing de modelos e AI Gateway neste contexto, com um posicionamento fundamentalmente diferente da integração tradicional de API de modelo único.
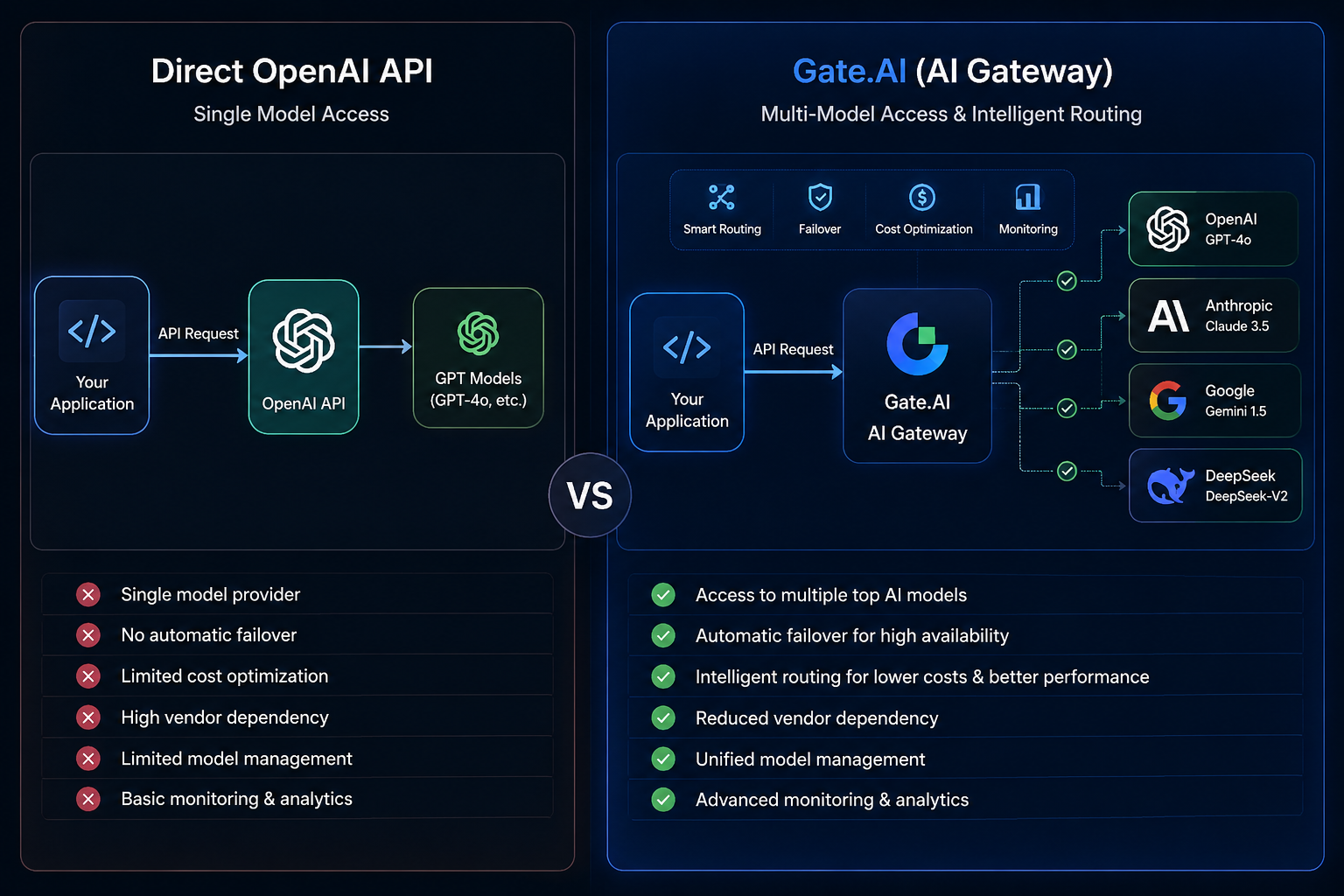
O que é a API da OpenAI?
A API da OpenAI é uma interface fornecida pela OpenAI que permite aos programadores invocar modelos da série GPT através de API padrão e integrá-los em chatbots, ferramentas de geração de conteúdo, sistemas de pesquisa e aplicações automatizadas.
Neste modelo, as aplicações enviam pedidos diretamente para a OpenAI, que devolve os resultados da inferência do modelo. Toda a cadeia de chamadas é relativamente simples; os programadores apenas precisam de gerir a interface de um único fornecedor para concluir a implementação.
Esta arquitetura é adequada para validação inicial de produtos, aplicações de modelo único e cenários com requisitos bem definidos. No entanto, à medida que a escala do negócio cresce, surgem problemas como seleção limitada de modelos, forte dependência do fornecedor e recuperação insuficiente de falhas.
O que é a Gate.AI?
A Gate.AI, enquanto plataforma de routing de modelos para aplicações de IA e agentes de IA, liga vários serviços de modelos de IA principais através de uma interface unificada.
Ao contrário de invocar diretamente um único modelo, a Gate.AI situa-se entre a aplicação e os serviços de modelo, atuando como um AI Gateway e ocupando-se do routing de modelos, da governança de pedidos e da comutação de modelos.
Os programadores não necessitam de desenvolver interfaces separadas para cada modelo; em vez disso, acedem aos modelos através de um ponto de entrada único. Quando um modelo fica indisponível, o sistema pode mudar automaticamente para outro modelo com base em regras predefinidas, melhorando assim a disponibilidade e a estabilidade gerais.
Como difere a cobertura de modelos da API da OpenAI da Gate.AI?
A cobertura de modelos é uma das diferenças mais evidentes entre as duas abordagens.
Ao invocar diretamente a API da OpenAI, os programadores podem aceder aos modelos fornecidos pela OpenAI, mas não podem utilizar diretamente outros serviços de modelo.
Em contraste, o objetivo de design da Gate.AI é agregar recursos de vários fornecedores, permitindo que os programadores acedam a diferentes capacidades através de uma única interface.
Por exemplo, uma aplicação pode usar GPT para tarefas de raciocínio complexo, Claude para análise de texto longo e DeepSeek para geração de código. Através da plataforma de routing, estas capacidades podem ser geridas de forma centralizada.
Esta abordagem ajuda a evitar a dependência de fornecedores e melhora a flexibilidade do sistema.
Diferenças arquitetónicas: AI Gateway vs. Integração de modelo único
Do ponto de vista arquitetónico, as duas soluções pertencem a camadas de infraestrutura diferentes.
Invocar diretamente a API da OpenAI é uma camada de aplicação que se liga diretamente a uma camada de modelo:
Aplicação → API da OpenAI → Modelo GPT
A Gate.AI insere uma camada AI Gateway entre elas:
Aplicação → Gate.AI → Ecossistema multi-modelo
As responsabilidades do AI Gateway vão além do simples encaminhamento de pedidos; incluem também:
- Routing de modelos
- Governança de pedidos
- Controlo de acesso
- Monitorização e auditoria
- Balanceamento de carga
- Recuperação de falhas
Portanto, não se trata de uma simples substituição; representam padrões arquitetónicos distintos adotados por sistemas de complexidade variada.
Como diferem as capacidades de controlo de custos da API da OpenAI e da Gate.AI?
À medida que a escala das aplicações de IA cresce, os custos de chamada de modelos tornam-se um fator importante.
Numa arquitetura de modelo único, todos os pedidos são enviados para o mesmo modelo, gerando o mesmo nível de custo de inferência mesmo quando certas tarefas não exigem o modelo de maior desempenho.
Uma plataforma de routing de modelos pode selecionar dinamicamente modelos com base na complexidade da tarefa.
Por exemplo:
- Perguntas e respostas simples utilizam modelos leves
- Resumo de conteúdo utiliza modelos médios
- Raciocínio complexo utiliza modelos de alto desempenho
Esta abordagem de escalonamento em camadas ajuda a melhorar a utilização de recursos e a reduzir os custos globais de inferência.
Assim, as arquiteturas multi-modelo oferecem tipicamente um maior potencial de otimização de custos do que as arquiteturas de modelo fixo.
Como diferem a recuperação de falhas e a disponibilidade da API da OpenAI e da Gate.AI?
As aplicações de IA têm exigências cada vez maiores de estabilidade.
Quando os programadores integram diretamente um serviço de modelo único, os pedidos podem falhar diretamente se o serviço sofrer paragens, tempos limite de resposta ou limitação de taxa.
Uma arquitetura de gateway multi-modelo pode alcançar a recuperação automática de falhas através de um mecanismo de fallback.
Quando o modelo primário não responde, o sistema pode redirecionar automaticamente o pedido para um modelo de backup.
Este mecanismo reduz o risco de pontos únicos de falha e melhora a operação contínua do sistema.
Para agentes de IA de longa duração ou fluxos de trabalho automatizados, a transferência de modelos tornou-se uma capacidade chave de infraestrutura.
Diferenças principais entre a Gate.AI e a API da OpenAI
| Dimensão de comparação |
Gate.AI |
API da OpenAI |
| Posicionamento |
Plataforma AI Gateway e routing de modelos |
Interface de serviço de modelo único |
| Fonte de modelos |
Ecossistema multi-modelo |
Modelos OpenAI |
| Comutação de modelos |
Suportada |
Não suportada |
| Fallback automático |
Suportado |
Não suportado |
| Gestão centralizada |
Suportada |
Limitada |
| Otimização de custos |
Suporta routing dinâmico |
Chamada de modelo fixa |
| Adaptabilidade a agentes de IA |
Alta |
Média |
| Dependência de fornecedores |
Baixa |
Alta |
| Extensibilidade |
Forte |
Relativamente limitada |
Que cenários são adequados para invocar diretamente a API da OpenAI?
Para validação de protótipos, projetos pequenos e aplicações que dependem especificamente de modelos GPT, invocar diretamente a API da OpenAI permite tipicamente uma implementação rápida com menor complexidade.
Quando o sistema é de pequena escala, os requisitos de modelo são singulares e os requisitos de recuperação de falhas são baixos, a arquitetura de modelo único oferece as vantagens de baixo custo de implementação e manutenção simples.
Que cenários são mais adequados para utilizar a Gate.AI?
Para produtos de IA de longa duração, aplicações de nível empresarial e sistemas de agentes de IA, as capacidades de gestão multi-modelo são frequentemente mais importantes do que as capacidades de modelo único.
Quando o sistema exige:
- Utilizar vários modelos em simultâneo
- Reduzir a dependência do fornecedor
- Comutação automática de falhas
- Otimização de custos
- Governança e monitorização centralizadas
Uma arquitetura AI Gateway proporciona tipicamente maior flexibilidade e escalabilidade.
Resumo
A diferença entre a Gate.AI e a invocação direta da API da OpenAI resume-se essencialmente à diferença entre uma arquitetura AI Gateway e uma arquitetura de integração de modelo único.
A API da OpenAI fornece acesso direto a um ecossistema de modelo único, adequado para construir e implementar rapidamente aplicações de IA; a Gate.AI, por outro lado, oferece suporte de infraestrutura para colaboração multi-modelo, sistemas de alta disponibilidade e agentes de IA através de routing de modelos e de um mecanismo de gateway unificado.
Perguntas Frequentes
A API da OpenAI e a Gate.AI são concorrentes?
As duas soluções não estão exatamente ao mesmo nível. A API da OpenAI é um fornecedor de serviços de modelo, enquanto a Gate.AI é uma plataforma de routing de modelos e AI Gateway que pode incluir os modelos OpenAI como um dos seus recursos acessíveis.
A Gate.AI liga-se apenas a modelos OpenAI?
Não. O objetivo da Gate.AI é unificar o acesso a múltiplos ecossistemas de modelos de IA, permitindo que os programadores acedam a diferentes capacidades através de uma única interface.
O que é um AI Gateway?
Um AI Gateway é uma camada de infraestrutura entre aplicações e modelos, responsável pelo encaminhamento de pedidos, routing de modelos, gestão de permissões, monitorização e governança, e recuperação de falhas.
O que significa o mecanismo de fallback?
Fallback é um mecanismo automático de recuperação de falhas. Quando o modelo primário está indisponível, o sistema muda automaticamente para um modelo de backup para continuar a processar o pedido, reduzindo assim o risco de interrupção do serviço.
Utilizar um AI Gateway significa que não é possível selecionar diretamente um modelo?
Não. Um AI Gateway suporta tipicamente tanto o routing automático de modelos como a especificação manual do modelo alvo pelos programadores; ambos os modos podem ser configurados de forma flexível com base nas necessidades específicas.









