人工智能的发展正在改变全球半导体产业格局。随着大语言模型、生成式 AI 和高性能计算需求快速增长,计算芯片需要处理的数据量呈指数级上升。在此背景下,传统存储技术逐渐面临带宽与能耗瓶颈,而能实现高速数据传输的 HBM(高带宽存储器)成为 AI 基础设施建设的重要环节。
在全球 HBM 市场中,SK 海力士占有举足轻重的地位。身为全球领先的存储芯片制造商之一,SK 海力士不仅长期深耕 DRAM 技术,更率先投入 HBM 产品研发与量产体系。随着 AI GPU 对高速存储需求持续攀升,SK 海力士逐渐成为 AI 存储芯片产业链中的关键供应商。
什么是 HBM?
HBM(High Bandwidth Memory)是一种高带宽存储器技术,主要针对人工智能、高性能计算(HPC)、数据中心与图形处理等场景设计。相较于传统 DRAM,HBM 能在更小空间内提供更高的数据传输能力。
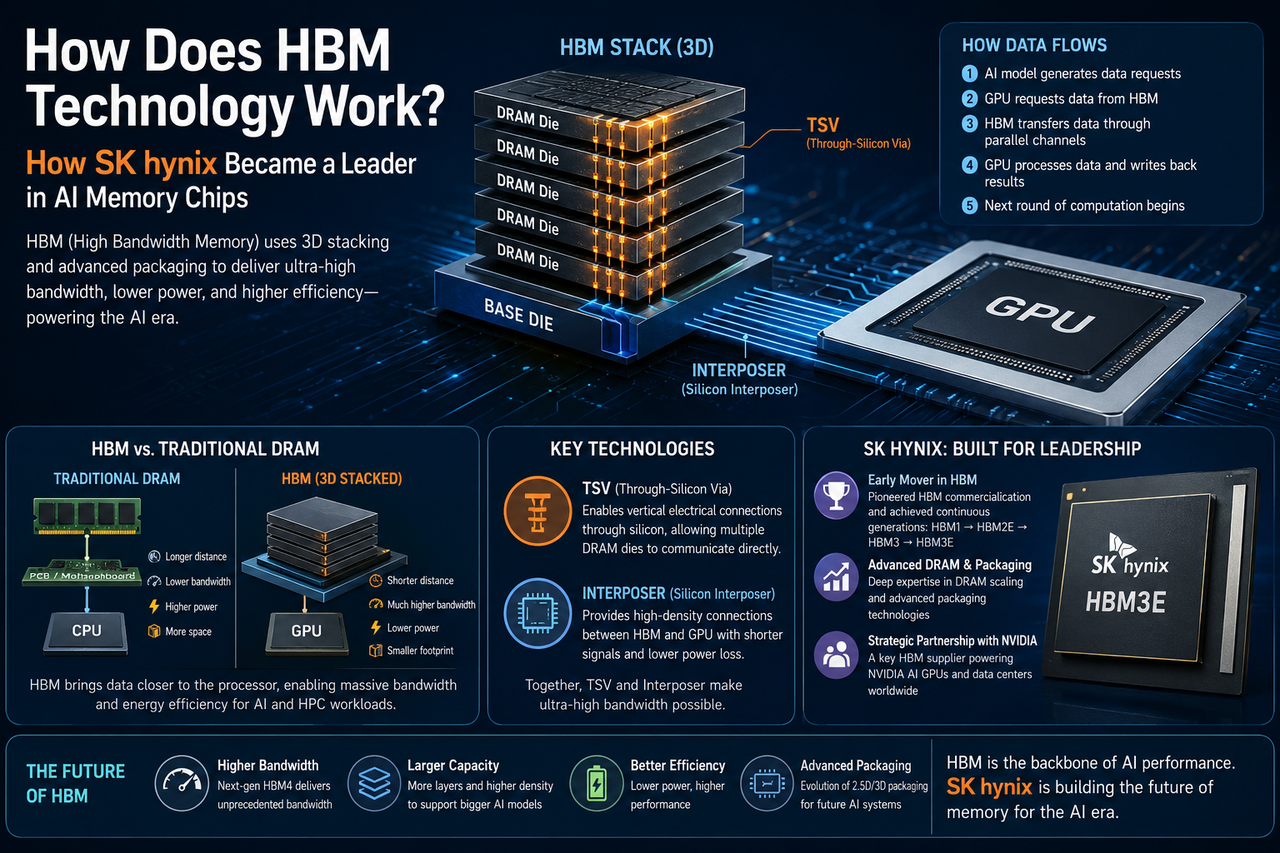
HBM 的核心特色在于采用三维堆叠(3D Stacking)结构,将多个 DRAM 芯片垂直堆叠,并通过 TSV(Through-Silicon Via,硅穿孔)技术实现高速连接。由于数据传输路径更短,HBM 能大幅提升带宽并降低功耗。
为何传统 DRAM 难以满足 AI 需求?
传统 DRAM 长期是计算机与服务器的主流存储方案,但 AI 时代的数据规模已远超传统计算场景。
在大模型训练过程中,GPU 需要不断读取与写入海量参数。若数据传输速度跟不上计算速度,即使 GPU 拥有强大计算能力,也会因等待数据而导致性能浪费。
传统 DRAM 面临以下挑战:
| 挑战 | 传统 DRAM 表现 |
|---|---|
| 带宽限制 | 数据吞吐能力有限 |
| 功耗较高 | 数据传输距离较长 |
| 空间占用较大 | 难以满足高密度部署 |
| AI 扩展能力 | 多 GPU 系统效率下降 |
因此,业界开始寻求更适合 AI 场景的新型存储解决方案,HBM 因而快速发展。
HBM 技术如何运作?
HBM 的核心概念是缩短数据传输距离并扩大数据通道数量。
传统 DRAM 通常通过主板与处理器连接,而 HBM 则直接与 GPU 封装在同一系统中。多个 DRAM 芯片通过 TSV 技术垂直堆叠,并借助硅中介层连接 GPU,从而实现超高带宽通信。
整个数据传输流程大致如下:
-
AI 模型运行时产生大量数据请求;
-
GPU 向 HBM 发出读取指令;
-
HBM 通过并行数据通道快速传输数据;
-
GPU 完成计算后将结果写回存储系统;
-
新一轮计算继续执行。
这种设计能减少数据移动带来的延迟,并显著提升 AI 训练效率。
HBM 与传统 DRAM 的结构差异
| 对比维度 | HBM | 传统 DRAM |
|---|---|---|
| 芯片结构 | 3D 堆叠 | 平面布局 |
| 数据连接 | TSV + Interposer | PCB 线路 |
| 带宽 | 极高 | 中等 |
| 功耗 | 较低 | 较高 |
| 应用场景 | AI、GPU、HPC | PC、服务器 |
TSV 和 Interposer 为何重要?
TSV(Through-Silicon Via)是 HBM 实现三维堆叠的关键技术。TSV 可在芯片内部建立垂直连接通道,使多个存储层能直接通信。Interposer(硅中介层)则负责连接 GPU 与 HBM。相较于传统主板布线,Interposer 能提供更高密度的数据连接,并降低信号损耗。
这两项技术共同构成 HBM 的核心架构,也是其能实现超高带宽的重要原因。
HBM 在 AI 训练中扮演什么角色?
现代 AI 模型包含数十亿甚至数万亿参数,每次训练都需要读取大量数据。
若 GPU 计算速度远高于数据读取速度,系统就会出现“算力空转”现象。HBM 的作用是确保数据能持续、高速地供应给 GPU,从而提升整体训练效率。
在 AI 推理场景中,HBM 同样扮演重要角色。高速数据访问能力能缩短响应时间,提高模型推理性能。因此,HBM 已逐渐成为 AI 芯片架构中不可或缺的一环。
SK 海力士如何成为 HBM 领导者?
SK 海力士长期深耕 DRAM 技术,为 HBM 研发奠定了基础。
该公司是全球最早推动 HBM 商业化应用的企业之一。从 HBM1 到 HBM3E,SK 海力士持续提升带宽、容量与能效表现,并不断优化先进封装技术。

在 AI 热潮到来之前,HBM 市场规模相对有限,但 SK 海力士仍持续投入研发资源。当生成式 AI 与大模型带动市场需求爆发时,企业已具备成熟的技术储备与量产能力。
这种长期布局成为其建立竞争优势的重要关键。
SK 海力士与 NVIDIA 的合作关系
AI GPU 是 HBM 最大的应用市场之一,而 NVIDIA 则是全球 AI 芯片领域的重要参与者。
现代 AI GPU 需搭配大容量、高带宽存储系统运行。HBM 已成为高端 GPU 的标准配备,而 SK 海力士则是重要的 HBM 供应商之一。
这种合作关系使 SK 海力士能深度参与 AI 基础设施建设,也进一步提升其在全球半导体产业链中的战略地位。
HBM 的未来发展方向
随着 AI 模型规模持续扩大,HBM 技术也在不断演进。
未来的发展趋势主要包括:
| 技术方向 | 发展目标 |
|---|---|
| HBM4 | 更高带宽与容量 |
| 更高堆叠层数 | 提升存储密度 |
| 更先进封装 | 降低延迟与功耗 |
| AI 专用存储优化 | 提高训练效率 |
| Chiplet 架构融合 | 提升系统扩展性 |
未来 AI 芯片性能的提升不仅依赖 GPU 本身,也将越来越依赖存储系统的创新。
HBM 与 GDDR 有什么区别?
HBM 与 GDDR 都属于高性能存储器,但设计目标存在明显差异。
GDDR 主要应用于消费级显卡与图形处理场景,通过较高频率提升性能;HBM 则通过超宽总线与堆叠结构实现更高带宽与更低功耗。在 AI 训练、高性能计算与数据中心环境中,HBM 往往具有更明显的优势。
总结
HBM 是 AI 时代最重要的存储技术之一,通过 3D 堆叠、TSV 与硅中介层等先进技术,实现远超传统 DRAM 的带宽表现。随着大模型训练与高性能计算需求增长,HBM 已成为 AI GPU 与数据中心基础设施的重要组成部分。
SK 海力士凭借长期积累的 DRAM 技术、先进封装能力以及对 HBM 市场的持续投入,逐步建立起全球领先地位。从 AI 芯片到数据中心,从 GPU 到超级计算机,HBM 正成为支撑 AI 算力增长的重要基石,而 SK 海力士则是这一产业链中的核心参与者。
FAQs
HBM 为什么比传统 DRAM 更适合 AI?
HBM 能提供更高带宽、更低延迟与更低功耗。AI 模型训练需要持续读取大量数据,因此 HBM 更能满足 GPU 对高速存储的需求。
TSV 技术是什么?
TSV(Through-Silicon Via)是一种硅穿孔技术,可在多个堆叠芯片之间建立垂直连接通道。HBM 正是通过 TSV 实现高密度三维封装。
HBM 和 GDDR 有什么区别?
GDDR 主要针对图形处理场景,而 HBM 更适用于 AI、高性能计算与数据中心环境。HBM 通常拥有更高带宽与更优异的能效表现。
SK 海力士为什么在 HBM 市场领先?
SK 海力士较早布局 HBM 技术研发,并长期积累 DRAM 制造与先进封装经验。当 AI 市场需求增长时,企业已具备成熟的量产能力与技术优势。
HBM4 将带来哪些变化?
HBM4 预计将进一步提高带宽、容量与能效表现,并支持更大规模 AI 模型训练需求。随着 AI 算力持续增长,HBM4 有望成为下一代高性能计算平台的重要存储方案。
分享
目錄


相關文章

Jito 與 Marinade:Solana 流動性質押協議全面比較

Pharos 如何推动 RWA 上链?解析其 RealFi 基础设施逻辑

JTO 代幣經濟學深入解析:分配結構、用途及長期價值

Pharos 代幣經濟學深度解析:長期激勵機制、稀缺性模型及 RealFi 基礎設施的價值邏輯

Cardano vs 以太坊:兩大主流智能合約平台的本質差異
